在當(dāng)今數(shù)據(jù)驅(qū)動的時(shí)代,無論是大型電商平臺的秒殺活動,還是社交媒體平臺的實(shí)時(shí)信息流,亦或是金融科技的高頻交易,都對后端數(shù)據(jù)庫服務(wù)提出了前所未有的挑戰(zhàn):高容量的數(shù)據(jù)存儲與高并發(fā)的訪問處理。傳統(tǒng)的單機(jī)或主從架構(gòu)數(shù)據(jù)庫在TB/PB級數(shù)據(jù)量和每秒數(shù)十萬甚至百萬級TPS(每秒事務(wù)處理量)面前已力不從心。因此,構(gòu)建一個健壯、可擴(kuò)展、高性能的數(shù)據(jù)庫分布式架構(gòu),成為支撐現(xiàn)代互聯(lián)網(wǎng)業(yè)務(wù)的核心基石。本文將從一個技術(shù)專家的視角,深入解讀高容量大并發(fā)數(shù)據(jù)庫服務(wù)背后的分布式架構(gòu)設(shè)計(jì)思想、關(guān)鍵技術(shù)選型與核心挑戰(zhàn)。
一、核心挑戰(zhàn)與設(shè)計(jì)目標(biāo)
在設(shè)計(jì)高容量大并發(fā)數(shù)據(jù)庫服務(wù)之初,必須明確其面臨的核心挑戰(zhàn):
- 容量瓶頸:單臺服務(wù)器的存儲(磁盤)、內(nèi)存和計(jì)算(CPU)資源有限。
- 性能瓶頸:單點(diǎn)處理能力無法應(yīng)對海量并發(fā)讀寫請求,連接數(shù)、鎖競爭、I/O等待成為瓶頸。
- 可用性風(fēng)險(xiǎn):任何單點(diǎn)故障都可能導(dǎo)致服務(wù)不可用,無法滿足99.99%甚至更高的SLA(服務(wù)等級協(xié)議)。
- 擴(kuò)展不靈活:傳統(tǒng)架構(gòu)下,垂直擴(kuò)展(Scale-Up)成本高昂且存在上限,難以應(yīng)對業(yè)務(wù)的快速增長與波動。
因此,分布式架構(gòu)的設(shè)計(jì)目標(biāo)清晰而統(tǒng)一:可擴(kuò)展性(Scalability)、高可用性(High Availability)、高性能(Performance)和易維護(hù)性(Maintainability)。
二、分布式架構(gòu)的核心設(shè)計(jì)思想
為了達(dá)成上述目標(biāo),現(xiàn)代數(shù)據(jù)庫分布式架構(gòu)通常圍繞以下幾個核心思想展開:
1. 數(shù)據(jù)分片(Sharding/Partitioning)
這是解決容量和寫并發(fā)問題的根本方法。將整個數(shù)據(jù)集水平拆分,分散到多個數(shù)據(jù)庫節(jié)點(diǎn)(分片)上。
- 分片鍵選擇:至關(guān)重要,需選擇能均勻分布數(shù)據(jù)且頻繁用于查詢的字段(如用戶ID、訂單ID)。選擇不當(dāng)會導(dǎo)致“數(shù)據(jù)傾斜”,部分分片負(fù)載過重。
- 分片策略:常見的有范圍分片、哈希分片、一致性哈希等。哈希分片能保證數(shù)據(jù)均勻分布,但范圍查詢困難;一致性哈希在節(jié)點(diǎn)增刪時(shí)能最小化數(shù)據(jù)遷移。
- 分片位置透明性:對應(yīng)用層最好屏蔽分片細(xì)節(jié),由獨(dú)立的中間件(如ShardingSphere、Vitess)或數(shù)據(jù)庫原生能力(如MongoDB、CockroachDB)負(fù)責(zé)路由。
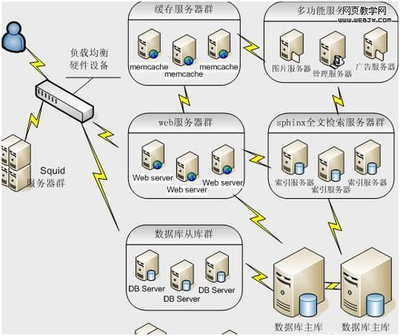
2. 讀寫分離與副本集(Replication)
這是提升讀并發(fā)能力和可用性的關(guān)鍵。
- 主從復(fù)制:一個主節(jié)點(diǎn)(Master)負(fù)責(zé)寫操作,多個從節(jié)點(diǎn)(Slave)異步或半同步復(fù)制主節(jié)點(diǎn)數(shù)據(jù),負(fù)責(zé)讀操作。這極大地分?jǐn)偭俗x壓力。
- 多副本高可用:采用一主多從,甚至多主多從架構(gòu)(如MySQL Group Replication, Galera)。當(dāng)主節(jié)點(diǎn)故障時(shí),能通過選舉機(jī)制快速自動切換(Failover)到健康的從節(jié)點(diǎn),保證服務(wù)不間斷。
- 全球分布式部署:在異地?cái)?shù)據(jù)中心部署副本,既能實(shí)現(xiàn)地理級別的容災(zāi),也能讓用戶就近讀取數(shù)據(jù),降低訪問延遲。
3. 分布式事務(wù)與一致性
這是分布式架構(gòu)中最復(fù)雜的一環(huán)。當(dāng)一次操作涉及多個分片時(shí),如何保證ACID特性?
- 強(qiáng)一致性模型:如使用兩階段提交(2PC)協(xié)議,但性能開銷大,存在阻塞風(fēng)險(xiǎn)。Google Spanner通過TrueTime API和Paxos協(xié)議實(shí)現(xiàn)了全球分布式下的強(qiáng)一致性,但架構(gòu)極其復(fù)雜。
- 最終一致性模型:這是互聯(lián)網(wǎng)分布式系統(tǒng)更常見的選擇。通過消息隊(duì)列、異步補(bǔ)償、版本向量等技術(shù),在確保系統(tǒng)高可用的前提下,允許數(shù)據(jù)在短暫時(shí)間內(nèi)不一致,但最終會達(dá)成一致。這需要業(yè)務(wù)邏輯有一定的容錯能力。
- NewSQL的探索:如TiDB、CockroachDB等NewSQL數(shù)據(jù)庫,嘗試在分布式環(huán)境下同時(shí)提供水平擴(kuò)展、高可用和強(qiáng)一致性(或跨行ACID事務(wù)),是當(dāng)前的技術(shù)熱點(diǎn)。
4. 彈性伸縮與無狀態(tài)化
為了應(yīng)對流量的潮汐效應(yīng),理想的架構(gòu)應(yīng)能實(shí)現(xiàn)彈性伸縮。
- 計(jì)算與存儲分離:將數(shù)據(jù)庫的計(jì)算層(SQL解析、優(yōu)化、執(zhí)行)與存儲層(數(shù)據(jù)持久化)分離。計(jì)算層可以輕松地水平擴(kuò)展以應(yīng)對并發(fā)請求,存儲層則可以獨(dú)立擴(kuò)展容量和IOPS。云數(shù)據(jù)庫(如AWS Aurora、阿里云PolarDB)是這一架構(gòu)的典范。
- 無狀態(tài)計(jì)算節(jié)點(diǎn):計(jì)算層節(jié)點(diǎn)不持久化用戶數(shù)據(jù),任何請求可以被任何計(jì)算節(jié)點(diǎn)處理。這使增加或減少計(jì)算節(jié)點(diǎn)變得非常簡單快速。
三、關(guān)鍵技術(shù)選型與典型架構(gòu)模式
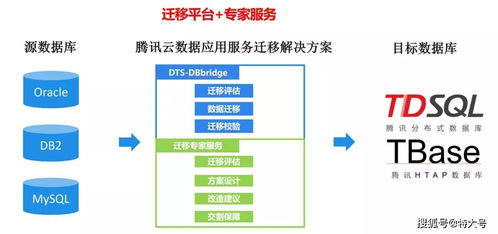
1. “中間件+傳統(tǒng)數(shù)據(jù)庫”模式
- 架構(gòu):使用獨(dú)立的代理中間件(如MyCAT、ShardingSphere-Proxy)對應(yīng)用層提供統(tǒng)一的SQL入口,中間件負(fù)責(zé)SQL解析、路由、結(jié)果聚合等。后端是多個分片的MySQL/PostgreSQL實(shí)例組(主從架構(gòu))。
- 優(yōu)點(diǎn):技術(shù)棧成熟,對現(xiàn)有業(yè)務(wù)侵入小,可充分利用傳統(tǒng)數(shù)據(jù)庫的生態(tài)和工具。
- 缺點(diǎn):架構(gòu)復(fù)雜,運(yùn)維成本高;中間件可能成為新的性能瓶頸和單點(diǎn);分布式事務(wù)支持弱。
2. 原生分布式數(shù)據(jù)庫
- 架構(gòu):直接采用為分布式而生的數(shù)據(jù)庫系統(tǒng),如TiDB(兼容MySQL協(xié)議)、CockroachDB(兼容PostgreSQL協(xié)議)、MongoDB Sharded Cluster、Cassandra等。
- 優(yōu)點(diǎn):開箱即用的分片、復(fù)制、故障轉(zhuǎn)移和(某種程度的)分布式事務(wù)能力,整體運(yùn)維復(fù)雜度相對較低。
- 缺點(diǎn):可能存在生態(tài)工具不如傳統(tǒng)數(shù)據(jù)庫豐富,特定場景下性能或功能有取舍,有被廠商鎖定的風(fēng)險(xiǎn)。
3. 云原生數(shù)據(jù)庫服務(wù)
- 架構(gòu):直接使用云廠商提供的全托管數(shù)據(jù)庫服務(wù),如AWS Aurora、Google Cloud Spanner、阿里云PolarDB for MySQL。
- 優(yōu)點(diǎn):極致簡化運(yùn)維,自動備份、擴(kuò)縮容、故障恢復(fù);通常采用計(jì)算存儲分離、日志即數(shù)據(jù)庫等先進(jìn)架構(gòu),提供極高的性能和可用性。
- 缺點(diǎn):成本較高,跨云遷移困難,深度定制能力受限。
四、實(shí)踐建議與
- 評估為先:不要為了分布式而分布式。首先明確業(yè)務(wù)的數(shù)據(jù)量、并發(fā)量、延遲和一致性要求。很多場景下,一個優(yōu)化良好的單機(jī)數(shù)據(jù)庫加上讀寫分離和緩存(如Redis)就足以應(yīng)對。
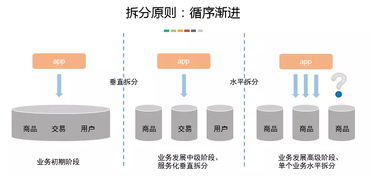
- 漸進(jìn)式演進(jìn):架構(gòu)演進(jìn)路徑可以是:主從復(fù)制 -> 讀寫分離+緩存 -> 垂直分庫(按業(yè)務(wù)拆分)-> 水平分片(按數(shù)據(jù)拆分)。
- 監(jiān)控與可觀測性:在分布式環(huán)境中,完善的監(jiān)控(資源、性能、慢查詢)和鏈路追蹤(Trace)是快速定位問題的生命線。
- 擁抱云原生:對于大多數(shù)企業(yè),從效率和成本角度考慮,直接采用成熟的云數(shù)據(jù)庫服務(wù)可能是最優(yōu)解,可以將精力聚焦于業(yè)務(wù)創(chuàng)新。
總而言之,設(shè)計(jì)高容量大并發(fā)數(shù)據(jù)庫服務(wù)的分布式架構(gòu),是一場在一致性、可用性、分區(qū)容錯性(CAP定理) 之間,以及在性能、復(fù)雜度、成本之間尋求最佳平衡的藝術(shù)。沒有銀彈,只有最適合當(dāng)前業(yè)務(wù)發(fā)展階段和技術(shù)團(tuán)隊(duì)能力的方案。隨著軟硬件技術(shù)的不斷發(fā)展,特別是云原生和NewSQL的成熟,構(gòu)建和維護(hù)此類系統(tǒng)的門檻正在逐步降低,但其核心的設(shè)計(jì)思想與權(quán)衡智慧,始終是每一位技術(shù)架構(gòu)師需要深刻理解和掌握的。